WordsEye Will Show What You Describe
Image-analyzing software has been a possibility for a while now. It’s how Google’s reverse image search works. It’s how you are able to deposit a check via ATM or even smartphone. Image creation is a newer development. Google’s Deep Dream, released last year, recreates images that are fed to it by compositing other images, shapes, and colors into a twisted version of the original. The obvious next step here is software that can create an image from a description, which WordsEye has gotten to first.
WordsEye is a new software that converts language to 3-D images. In its current beta state, WordsEye’s images are constructed from pre-existing, manipulatable 3-D models, textures, and light sources. The results are surreal, cartoon-y and a little unsettling. But don’t let this detract from such an advancement in artificial intelligence.
A basic description for WordsEye to interpret might look like this:
the silver fish is above the grey ground.
it is noon.
the orange light is below the fish.
three tiny red aliens are next to the fish.
the fire is behind the aliens.
the bright yellow light is above the fire.
The software would, then, create something that looks like this:
The program does this by using “a large database for linguistic and world knowledge about objects, their parts, and their properties,” to create semantic relationships between objects. A graphic on their website shows a basic breakdown of how it creates these relationships:
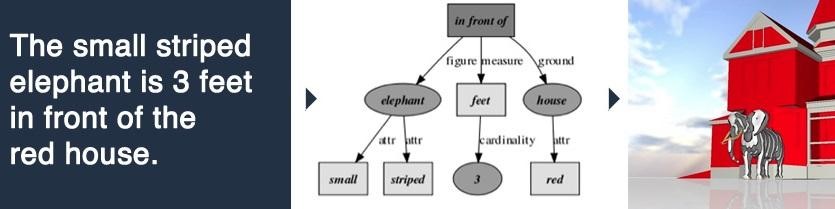
Basically, it analyzes all the what’s and the where’s that are entered into it. As the diagram shows, the prepositional phrase acts as the foundation for the scene, as it establishes the relationship between two or more parts. The elephant, the distance, and the house are all connected through “in front of.” If the program becomes more sophisticated, a verb could take the place of the prepositional phrase, making the relationship interactive instead of directional.
One of the more impressive aspects of WordsEye is its ability to place light sources that react realistically with the environment. In the first example, the orange and yellow lights reflect off the silver fish as well as cast overlapping shadows in believable ways considering the placement of the lights. These scenes can then be tweaked as well as looked at from any angle or distance, leaving an infinite number of possibilities to make your scene unique.
The program’s ability to “understand” words and their relationships is what qualifies it as “artificial intelligence.” Prior to this, a user would have to give all objects specific placements and dimensions, as if on a grid. Automating this process is made possible by giving all parts relative locations to each other.
Even in it’s beta state, the software provokes a lot of ideas for possible uses when integrated with other technology. Will the images and language recognition become more sophisticated, allowing for more complicated creations? Will it be paired with speech recognition software, allowing one to “tell” the computer about the desired image? Will the 3-D creations eventually be available to print using a 3-D printer? Will animating the images be possible using the same description-recognizing system? Will WordsEye become a legitimate SaaS company? How will this technology affect the video game industry?
The potential for this technology to carve out a place for itself in many different industries seems great. It will be exciting to watch how this program is adopted and adapted over the coming years.
About the Author:
 Dylan Eller is a freelance writer and musician from Boise, ID who writes about tech, current events, music, and science. He has been published on TechCrunch, IVN, Has It Leaked?, Astronaut, and more.
Dylan Eller is a freelance writer and musician from Boise, ID who writes about tech, current events, music, and science. He has been published on TechCrunch, IVN, Has It Leaked?, Astronaut, and more.







